Exploring AI's Shockwave through Data Stocks' Perceived Moats
Public markets are repricing ‘data businesses’ as if the interface is the product. The real question is who captures value when agents become the UI


Markets have spent the last couple of weeks repricing a familiar group of public companies, particularly financial and legal information services, like something structural has changed overnight. The headline explanation is simple: AI is changing how knowledge work gets done. But that explanation is incomplete and maybe even "shockingly misguided". What’s actually being repriced is where value accrues in the information stack:
- Is the profit pool in the data layer (rights, provenance, normalization)?
- Or in the workflow layer (embedded execution, integrations, daily habits)?
- Or in the interface layer (the “assistant” users actually touch)?
The volatility seems to imply the market is wrestling with one key question:
If agents become the primary UI for research and compliance work, do incumbents remain platforms—or become inputs?
Signals from Alt Data Breakfast #4: The Future of Alt Data + AI
Last week I hosted a panel discussion with an audience of 70+ data/investing professionals exploring the present and future of AI agents in the alternative data and asset management industries. I explained much of what I've written about here and then solicited the opinions of the crowd on this subject. Somewhat surprisingly (to me, at least) about half believed the selloff in these public companies was overblown and half thought it was warranted, despite my biased (towards it being overblown) introduction to the subject.
Relatedly, my panelists and I discussed at length the potential shift in data buying/procurement behaviors in this age of AI agents. Tim Baker's venture ViaNexus and Freeman Lewin's Brickroad are both AI-native data providers ready for a world where AI agents autonomously source, buy and consume data under a consumption-based pricing model. I represented the devil's advocate position, in which the larger data buyers would likely want to keep the current yearly data licensing "all-you-can-eat" model. And when posing this debate to the audience, the most suprising (and enlightening?) part of the whole morning was that two thirds or so thought consumption-based data procurement models would be much more common for hedge funds in the near future.
Anecdotally, I've also been hearing about attempts from these companies to significantlly raise their prices beyond the normal course of business and to lock in longer-term contracts. While interesting, I don't believe we can draw any concrete conclusions from this. It can either be a sign of these companies' monopolistic pricing power or desperation for incremental revenue, or a bit of both.
Prevailing Wisdom: “AI Disintermediates Incumbents”
The dominant narrative has three parts:
- Agents reduce the need for traditional terminals and research workflows.
If an assistant can pull from multiple sources and execute tasks, the incumbent UI could lose its role as the “home screen.” - Moat skepticism drives multiple compression.
These businesses historically traded as “quality compounders.” If the moat is questioned (even before fundamentals deteriorate) valuation can reset quickly. - Guidance and tone amplify the move.
When a bellwether hints at slower growth, investors extrapolate “duration risk” across the category.
That’s the story most people are telling. Directionally plausible—but not the whole picture.
What Might Actually be Happening
In concentrated selloffs, fundamentals are often only part of the cause. Several under-discussed drivers can create synchronized, exaggerated moves across a cohort:
1) Crowding + factor unwinds (the mechanical sell)
Many of these names live in “quality / low-vol / defensive growth” buckets. When systematic strategies de-risk, crowded “safe” holdings can sell off together—regardless of company-specific news.
2) Options positioning & dealer hedging (the accelerant)
When key names break levels into heavy put positioning, dealer hedging can magnify intraday downside. That can turn a normal 2–3% move into 5–9% air pockets.
3) Procurement behavior shifts (quiet at first, loud later)
Even with stable retention, procurement teams can begin pushing:
- Tool consolidation
- Flat renewals
- Outcome-based pricing
These shifts often surface first as tone and guidance framing, not headline churn.
4) Licensing economics uncertainty (tollbooth vs platform)
Markets are struggling to price whether incumbents:
- Become toll collectors (licensing data into many agents), or
- Get commoditized (agents make “good enough” substitutes viable)
The dispersion in outcomes is itself volatility fuel.
Are Investors Underestimating Defensibility?
I believe there’s a strong case investors are underestimating the “industrial capability” moat these firms have built:
- Sourcing rights & exclusivity (contracts, exchanges, publishers, direct contributors)
- Cleaning / normalization / entity resolution (the hard part most people ignore)
- Historical linkage across time (corporate actions, identifiers, mapping)
- Compliance-grade provenance (auditability, traceability, reproducibility)
- Switching costs (integrations and downstream dependency)
If your workflows are regulated or mission-critical, “pretty answers” don’t win. Verifiable answers do.
So why the repricing? Because:
Moat ≠ monetization if the UI changes.
Even a world-class data moat can produce lower returns if the business shifts from:
- Platform economics (high-margin workflow + distribution + bundling), to
- Utility economics (licensed inputs, thinner margins, lower pricing power)
A Simplified Framework: The 2×2 Data Moat Map
To make the debate more concrete, it's useful to map these companies in a simplified two-axis data moat framework (while recognizing the real-world multi-dimensional nature of this):
- Data Moat (Y): rights, provenance, entity mastery, proprietary coverage
- Workflow Moat (X): proprietary/specialized software/technology, embedded execution, integrations, daily jobs-to-be-done
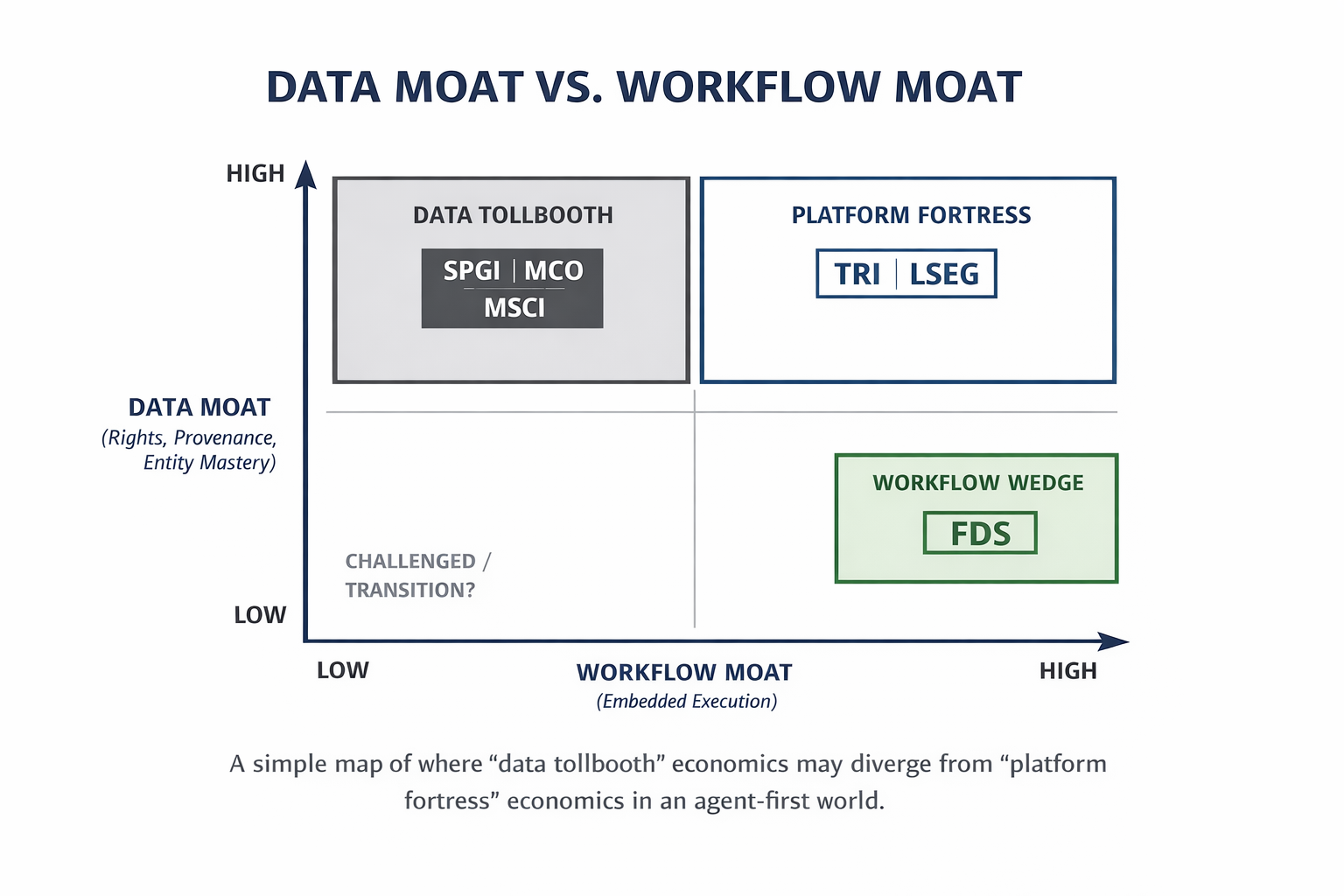
The Subset of Data Companies We're Mapping
I've chosen a subset of 6 publicly traded stocks to illustrate this framework based on those that I perceive to be most embedded in institutional investors' workflows.
Platform Fortress (top-right: high data / high workflow):
- TRI (Thomson Reuters)
- LSEG (London Stock Exchange Group / Refinitiv)
Data Tollbooth (top-left: high data / moderate workflow):
- SPGI (S&P Global)
- MCO (Moody’s)
- MSCI (MSCI)
Workflow Wedge (bottom-right: moderate data / high workflow):
- FDS (FactSet)
Challenged / Transition (bottom-left):
- We've decided not to include any of these as they will likely lose relevance in the near future.
Interpretation:
- Fortress names can plausibly keep workflow + data economics even as interfaces evolve.
- Tollbooth names remain essential, but risk shifting toward licensed-input economics unless they deepen workflow control.
- Workflow wedge names must prove the agent “lives inside” their workstation, not above it.
How to Conclusively Resolve this Debate
The fastest way to separate “AI narrative volatility” from “fundamental moat impairment” is to track a small set of theses and KPIs about these companies.
TRI — Thomson Reuters
Core question: can TR keep the “trusted answer + execution” loop inside its ecosystem?
Watch for:
- Renewal / net retention language in legal
- AI attach / tiering (is AI monetized or bundled free?)
- Evidence of workflow execution, not just chat/search (drafting, filing, matter workflows)
- Packaging shifts (seat → workflow / matter pricing)
Red flags:
- “AI included at no incremental cost”
- Increasing discounting to protect renewals
- Consolidation-driven churn
LSEG — Refinitiv
Core question: platform UI vs premium feed in someone else’s agent stack?
Watch for:
- Workspace seat trends + renewal tone
- Enterprise feed expansion even if UI shifts
- Partner economics (rev share vs flat licensing; channel control)
- Narrative emphasis on real-time differentiation / “must-have” data
Red flags: - Frequent “LLM layer over multiple feeds” anecdotes
- More concessions on enterprise pricing
FDS — FactSet
Core question: does FactSet become the research OS for agents?
Watch for:
- Workstation retention + usage (qualitative is fine)
- AI module adoption and willingness-to-pay
- Land/expand acceleration tied to AI-enabled workflows
- Margin mix (watch services creep from AI customization)
Red flags: - Stable retention but deteriorating price uplift
- Agent abstraction reducing workstation dependence
SPGI — S&P Global
Core question: unified workflow capture vs federation into licensing inputs?
Watch for:
- Segment-level guide tone (where is deceleration showing up?)
- Adoption of AI features inside core products (beyond search)
- Cross-sell/attach improvement (AI should increase wallet share if it’s real)
- Pricing power (discounting / bundling vs premium tiers)
Red flags: - Procurement-led simplification
- Pricing pressure masked by mix
MCO — Moody’s
Core question: does GenAI increase stickiness or get replicated in-house?
Watch for:
- Momentum in analytics + research products
- Disclosures on GenAI adoption and deal attribution
- Emphasis on explainability/governance as a differentiator
- Changes in renewal concession behavior
Red flags:
- “One of many sources behind an enterprise agent” positioning
- Pricing pressure in analytics
MSCI — MSCI
Core question: does AI deepen the methodology moat—or commoditize the interface?
Watch for:
- Analytics retention/expansion (module attach, penetration into process)
- Evidence AI features drive incremental wallet share
- Messaging around governance + methodology defensibility
- Sensitivity disclosures around index-linked economics (context, not the whole story)
Red flags: - Increasing narrative that “risk/factor outputs are interchangeable” inside agent tooling
The Wildcards
Three unknowns will determine who wins this cycle:
- Substitution vs augmentation
Do agents reduce seats, or increase usage by lowering friction? - Who owns agent distribution
Incumbents (e.g., ChatGPT), enterprise suites (e.g., Microsoft), or specialist AI-native vendors (e.g. AlphaSense)? - Content/data rights economics
Does licensing become a high-margin tollbooth—or a race to the bottom?
Until those resolve, expect volatility to remain clustered and narrative-driven.
The Moat is Real, it's the Economics that are Shifting
The strongest takeaway is subtle:
It's not about whether investors are underestimating the data moat (although I think they are). But they've certainly underestimated how quickly monetization can shift when the UI changes.
This is why the best diligence now isn’t only “how unique is the data?”
It’s: “Where does the agent live, and who gets paid when work gets done?”
For research and discussion purposes only. Not investment advice.